We can group the resultset in SQL on multiple column values. All the column values defined as grouping criteria should match with other records column values to group them to a single record. Let us use the aggregate functions in the group by clause with multiple columns. This means given for the expert named Payal, two different records will be retrieved as there are two different values for session count in the table educba_learning that are 750 and 950. Grouping on multiple columns is most often used for generating queries for reports, dashboarding, etc.

Group by is done for clubbing together the records that have the same values for the criteria that are defined for grouping. When a single column is considered for grouping then the records containing the same value for that column on which criteria are defined are grouped into a single record for the resultset. There's an additional way to run aggregation over a table. If a query contains table columns only inside aggregate functions, the GROUP BY clause can be omitted, and aggregation by an empty set of keys is assumed. The SQL GROUP BY Statement The GROUP BY statement groups rows that have the same values into summary rows, like "find the number of customers in each country".

The GROUP BY statement is often used with aggregate functions to group the result-set by one or more columns. A complete guide on sql function sum with find total on multiple columns, sum group by, sum of two columns, where clause, average of sum, aggregate functions. NET Database SQL MySQL PostgreSQL SQLite NoSQL SQL SUM() function with group by The aggregate functions summarize the table data. The aggregate functions are applied in order to return just one value per group. All the expressions in the SELECT, HAVING, and ORDER BY clauses must be calculated based on key expressions or on aggregate functions over non-key expressions . In other words, each column selected from the table must be used either in a key expression or inside an aggregate function, but not both.

The SQL GROUP BY Clause is used to output a row across specified column values. It is typically used in conjunction with aggregate functions such as SUM or Count to summarize values. Rather than returning every row in a table, when values are grouped, only the unique combinations are returned. This syntax allows users to perform analysis that requires aggregation on multiple sets of columns in a single query. Complex grouping operations do not support grouping on expressions composed of input columns. If the WITH TOTALS modifier is specified, another row will be calculated.

This row will have key columns containing default values , and columns of aggregate functions with the values calculated across all the rows (the "total" values). SQL SUM() function with group by SUM is used with a GROUP BY clause. Once the rows are divided into groups, the aggregate functions are applied in order to return just one value per group.

Pandas comes with a whole host of sql-like aggregation functions you can apply when grouping on one or more columns. This is Python's closest equivalent to dplyr's group_by + summarise logic. Here's a quick example of how to group on one or multiple columns and summarise data with aggregation functions using Pandas. It filters non-aggregated rows before the rows are grouped together. To filter grouped rows based on aggregate values, use the HAVING clause.

The HAVING clause takes any expression and evaluates it as a boolean, just like the WHERE clause. As with the select expression, if you reference non-grouped columns in the HAVINGclause, the behavior is undefined. The GROUP BY clause is often used with aggregate functions such as AVG(), COUNT(), MAX(), MIN() and SUM().

In this case, the aggregate function returns the summary information per group. For example, given groups of products in several categories, the AVG() function returns the average price of products in each category. The GROUP BY clause is used in a SELECT statement to group rows into a set of summary rows by values of columns or expressions. First, you specify a column name or an expression on which to sort the result set of the query. If you specify multiple columns, the result set is sorted by the first column and then that sorted result set is sorted by the second column, and so on. To be perfectly honest, whenever I have to use Group By in a query, I'm tempted to return back to raw SQL.

I find the SQL syntax terser, and more readable than the LINQ syntax with having to explicitly define the groupings. In an example like those above, it's not too bad keeping everything in the query straight. However, once I start to add in more complex features, like table joins, ordering, a bunch of conditionals, and maybe even a few other things, I typically find SQL easier to reason about. Once I get to the point where I'm using LINQ to group by multiple columns, my instinct is to back out of LINQ altogether. However, I recognize that this is just my personal opinion.
If you're struggling with grouping by multiple columns, just remember that you need to group by an anonymous object. If you've used ASP.NET MVC for any amount of time, you've already encountered LINQ in the form of Entity Framework. EF uses LINQ syntax when you send queries to the database. While most of the basic database calls in Entity Framework are straightforward, there are some parts of LINQ syntax that are more confusing, like LINQ Group By multiple columns.

The GROUP BY clause is used in conjunction with the aggregate functions to group the result-set by one or more columns. The GROUP BY statement is often used with aggregate functions ( COUNT() , MAX() , MIN() , SUM() , AVG() ) to group the result-set by one or more columns. The GROUP BY clause divides the rows returned from the SELECTstatement into groups.

For each group, you can apply an aggregate function e.g.,SUM() to calculate the sum of items or COUNT()to get the number of items in the groups. When you use a GROUP BY clause, you will get a single result row for each group of rows that have the same value for the expression given in GROUP BY. Instructions for aggregation are provided in the form of a python dictionary or list. The dictionary keys are used to specify the columns upon which you'd like to perform operations, and the dictionary values to specify the function to run.

The aggregation can be performed more effectively, if a table is sorted by some key, and GROUP BY expression contains at least prefix of sorting key or injective functions. In this case when a new key is read from table, the in-between result of aggregation can be finalized and sent to client. This behaviour is switched on by the optimize_aggregation_in_order setting. Such optimization reduces memory usage during aggregation, but in some cases may slow down the query execution.

WITH CUBE modifier is used to calculate subtotals for every combination of the key expressions in the GROUP BY list. WITH ROLLUP modifier is used to calculate subtotals for the key expressions, based on their order in the GROUP BY list. Even though the database creates the index for the primary key automatically, there is still room for manual refinements if the key consists of multiple columns.

In that case the database creates an index on all primary key columns—a so-called concatenated index (also known as multi-column, composite or combined index). Note that the column order of a concatenated index has great impact on its usability so it must be chosen carefully. The SQL COUNT () function returns the number of rows in a table satisfying the criteria specified in the WHERE clause. SUM() function with group by It is better to identify each summary row by including the GROUP BY clause in the query resulst.

All columns other than those listed in the GROUP BY clause must have an aggregate function applied to them. When you use the SELECT statement to query data from a table, the order of rows in the result set is not guaranteed. It means that SQL Server can return a result set with an unspecified order of rows. If you want to break your output into smaller groups, if you specify multiple column names or expressions in the GROUP BY clause. Output in each group must satisfy a specific combination of the expressions listed in the GROUP BY clause. The more columns or expressions entered in the GROUP BY clause, the smaller the groups will be.

We can observe that for the expert named Payal two records are fetched with session count as 1500 and 950 respectively. Note that the aggregate functions are used mostly for numeric valued columns when group by clause is used. Criteriacolumn1 , criteriacolumn2,…,criteriacolumnj – These are the columns that will be considered as the criteria to create the groups in the MYSQL query.

There can be single or multiple column names on which the criteria need to be applied. SQL does not allow using the alias as the grouping criteria in the GROUP BY clause. Note that multiple criteria of grouping should be mentioned in a comma-separated format. Aggregate_function – These are the aggregate functions defined on the columns of target_table that needs to be retrieved from the SELECT query. You can use any of the grouping functions in your select expression. Their values will be calculated based on all the rows that have been grouped together for each result row.

If you select a non-grouped column or a value computed from a non-grouped column, it is undefined which row the returned value is taken from. This is not permitted if the ONLY_FULL_GROUP_BY SQL_MODE is used. When multiple statistics are calculated on columns, the resulting dataframe will have a multi-index set on the column axis. The multi-index can be difficult to work with, and I typically have to rename columns after a groupby operation. The output from a groupby and aggregation operation varies between Pandas Series and Pandas Dataframes, which can be confusing for new users. As a rule of thumb, if you calculate more than one column of results, your result will be a Dataframe.
For a single column of results, the agg function, by default, will produce a Series. In the subtotals rows the values of already "grouped" key expressions are set to 0 or empty line. Here, the grouped result data is sorted by the Total Earning of each group in descending order in mysql group by multiple columns. The HAVING clause with SQL COUNT () function can be used to set a condition with the select statement. The HAVING clause is used instead of WHERE clause with SQL COUNT () function.

The GROUP BY with HAVING clause retrieves the result for a specific group of a column, which matches the condition specified in the HAVING clause. SUM of Multiple columns of MySQL table Now we will learn how to get the query for sum in multiple columns and for each record of a table. 3 and then divide that from the total and multiply with 100 here is the query. SQL Server allows you to sort the result set based on the ordinal positions of columns that appear in the select list. It is possible to sort the result set by a column that does not appear on the select list.

For example, the following statement sorts the customer by the state even though the state column does not appear on the select list. It's simple to extend this to work with multiple grouping variables. Say you want to summarise player age by team AND position.

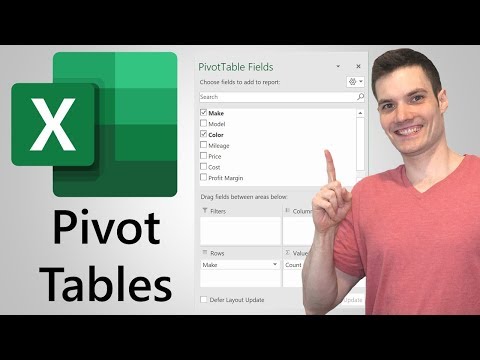
You can do this by passing a list of column names to groupby instead of a single string value. Often you may want to group and aggregate by multiple columns of a pandas DataFrame. Fortunately this is easy to do using the pandas.groupby()and.agg()functions. In this tutorial, you have learned you how to use the PostgreSQL GROUP BY clause to divide rows into groups and apply an aggregate function to each group. You can use the GROUP BYclause without applying an aggregate function.

The following query gets data from the payment table and groups the result by customer id. In this power bi tutorial, we learned power bi sum group by multiple columns. And also we discussed the below points power bi sum group by two columns using power query. You can query data from multiple tables using the INNER JOIN clause, then use the GROUP BY clause to group rows into a set of summary rows. For each group, you can apply an aggregate function such as MIN, MAX, SUM, COUNT, or AVG to provide more information about each group. In this tutorial, we have shown you how to use the GROUP BY clause to summarize rows into groups and apply the aggregate function to each group.

Can We Use Two Columns In Group By Pandas groupby is a powerful function that groups distinct sets within selected columns and aggregates metrics from other columns accordingly. Remember that you can pass in custom and lambda functions to your list of aggregated calculations, and each will be passed the values from the column in your grouped data. In the subtotals rows the values of all "grouped" key expressions are set to 0 or empty line.
The only difference is that the result set returns by MySQL query using GROUP BY clause is sorted and in contrast, the result set return by MySQL query using DISTICT clause is not sorted. With the next row value Take the nth row from each group if n is an int, or a subset of rows if n is a list of ints. In SQL Server we can find the maximum or minimum value from different columns of the same data type using different methods. As we can see the first solution in our article is the best in performance and it also has relatively compact code. Please consider these evaluations and comparisons are estimates, the performance you will see depends on table structure, indexes on columns, etc.

In this tutorial, you have learned how to use the SQL Server ORDER BY clause to sort a result set by columns in ascending or descending order. First, select the columns that you want to group e.g., column1 and column2, and column that you want to apply an aggregate function . The GROUP BY clause is an optional clause of the SELECT statement. The GROUP BY clause a selected group of rows into summary rows by values of one or more columns. In the following examples, df.index // 5 returns a binary array which is used to determine what gets selected for the groupby operation. Once the GroupBy object has been created, several methods are available to perform a computation on the grouped data.
These operations are similar to theaggregating API, window functions API, and resample API. The GROUP BY clause is an optional clause of the SELECT statement that combines rows into groups based on matching values in specified columns. In this article, I share a technique for computing ad-hoc aggregations that can involve multiple columns. This technique is easy to use and adapt for your needs, and results in code that's straight forward to interpret. To read it into memory with the proper dyptes, you need a helper function to parse the timestamp column.

This is because it's expressed as the number of milliseconds since the Unix epoch, rather than fractional seconds, which is the convention. Similar to what you did before, you can use the Categorical dtype to efficiently encode columns that have a relatively small number of unique values relative to the column length. It can be difficult to inspect df.groupby("state") because it does virtually none of these things until you do something with the resulting object. It delays virtually every part of the split-apply-combine process until you invoke a method on it.

The WITH ROLLUP modifer adds extra rows to the resultset that represent super-aggregate summaries. For a full description with examples, see SELECT WITH ROLLUP. The describe() output varies depending on whether you apply it to a numeric or character column.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.